B-Tree 기반 인덱스 동작 방식
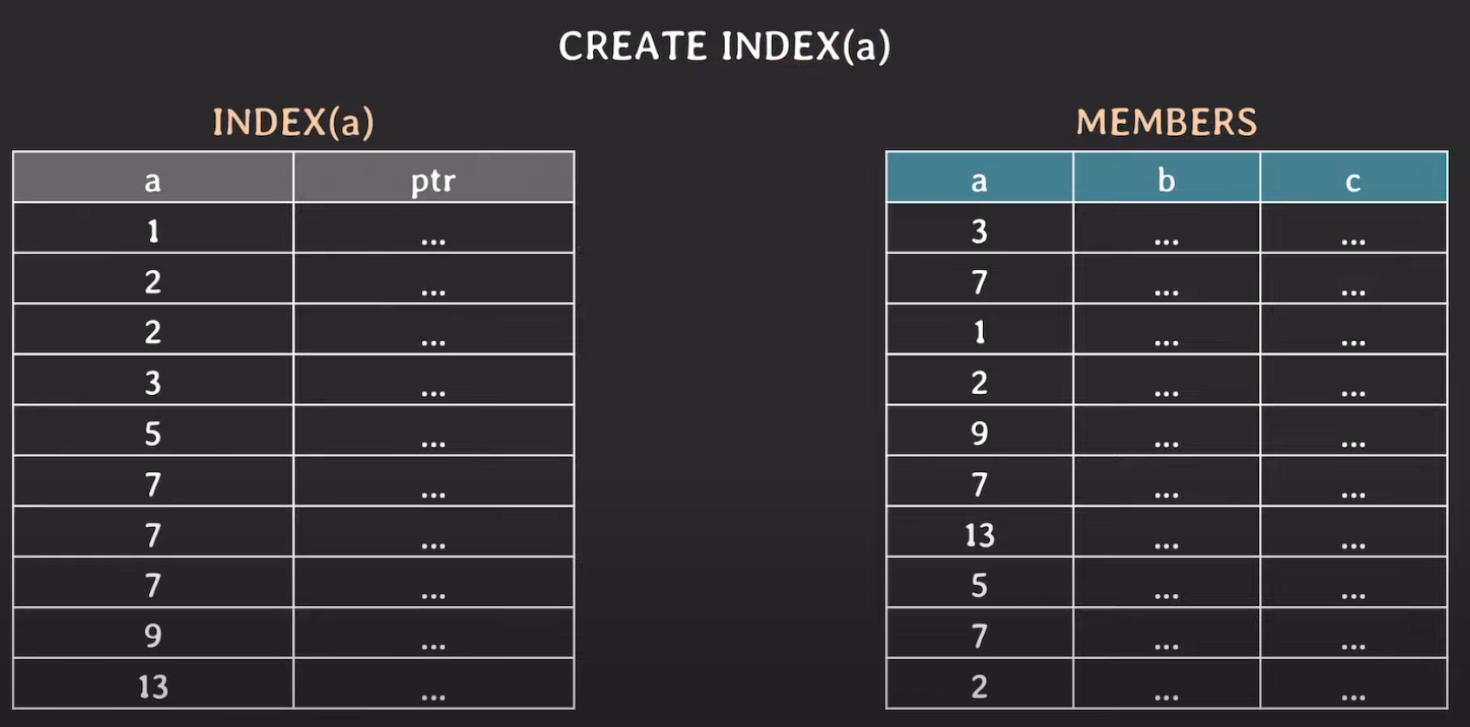
예를 들어 위와 같은 테이블이 있다고 가정해보자. 오른쪽은 실제 대상 테이블이고 왼쪽은 a컬럼에 대해서만 인덱스를 걸어둔 인덱스 정보라고 생각하면 된다. 인덱스 정보는 포인터(ptr)라는 데이터도 같이 가지고 있고 해당 포인터는 실제 MEMBMERS 테이블의 로우 위치를 가리키고 있다. 또한 인덱스 대상 컬럼을 기준으로 오름차순 정렬이 되어 저장된다.
예시 1
WHERE a = 9 라는 조건절을 통해 쿼리를 날린다고 생각해보자. 인덱스 테이블을 검색할 때 순차적으로 검색하는것이 아닌 Binary search를 하게 된다. 단계를 살펴보자면 아래와 같다.
- 인덱스 테이블에서 가운데 값인 5로 간다. 그리고 WHERE 조건과 동일한지 비교한다.
- 동일한 5와 9는 같지 않다. 따라서 5와 9를 비교하는데 WHERE 조건인 9보다 5가 더 작기 때문에 5보다 작은 값들은 서칭하지 않고 5보다 큰 값들로 검색을 이어나간다.
- 마찬가지로 5보다 큰 값들 중 중간값인 7을 찾는다. 그리고 7과 9를 비교한다.
- 7과 9또한 같지 않고 9가 7보다 크기 때문에 7보다 큰 값들을 검색한다.
- 9와 WHERE 조건인 9가 같기 때문에 포인터에 연결된 실제 MEMBERS값으로 이동한다.
예시 2

WHERE a = 7 AND b = 95 라는 조건절을 통해 쿼리를 날린다고 생각해보자.
- 먼저 중간값인 5로 간다. WHERE 조건보다 작기 때문에 5보다 큰 범위로 이동한다.
- 중간값인 7로 간다. WHERE 조건과 같다. 하지만 AND b = 95 조건이 맞는지는 현재 인덱스 정보로는 확인할 수 없다. 따라서 포인터에 연결된 실제 MEMBERS 테이블로 이동하여 b값과 동일한지 검사한다.
- 인덱스 정보에는 a = 7이 여러개이기 때문에 모든 7정보들도 함께 검사한다.
a 컬럼에 대해서만 인덱스가 만들어져있는 상황에서 타 컬럼도 조건절에 포함되어있는 경우 a컬럼 조건에 대해서는 빠르게 찾을 수 있다. 하지만 b 컬럼 조건에 대해서도 검사를 해줘야하는데, 인덱스 정보에는 존재하지 않기 때문에 실제 MEMBERS 테이블에 접근하여 데이터를 비교해야한다. 따라서 a 컬럼에 대해서는 인덱스를 타지만 그 결과로 나온 값들에 대해서는 b 컬럼 데이터를 찾기 위해 테이블 풀 스캔이 발생한다.
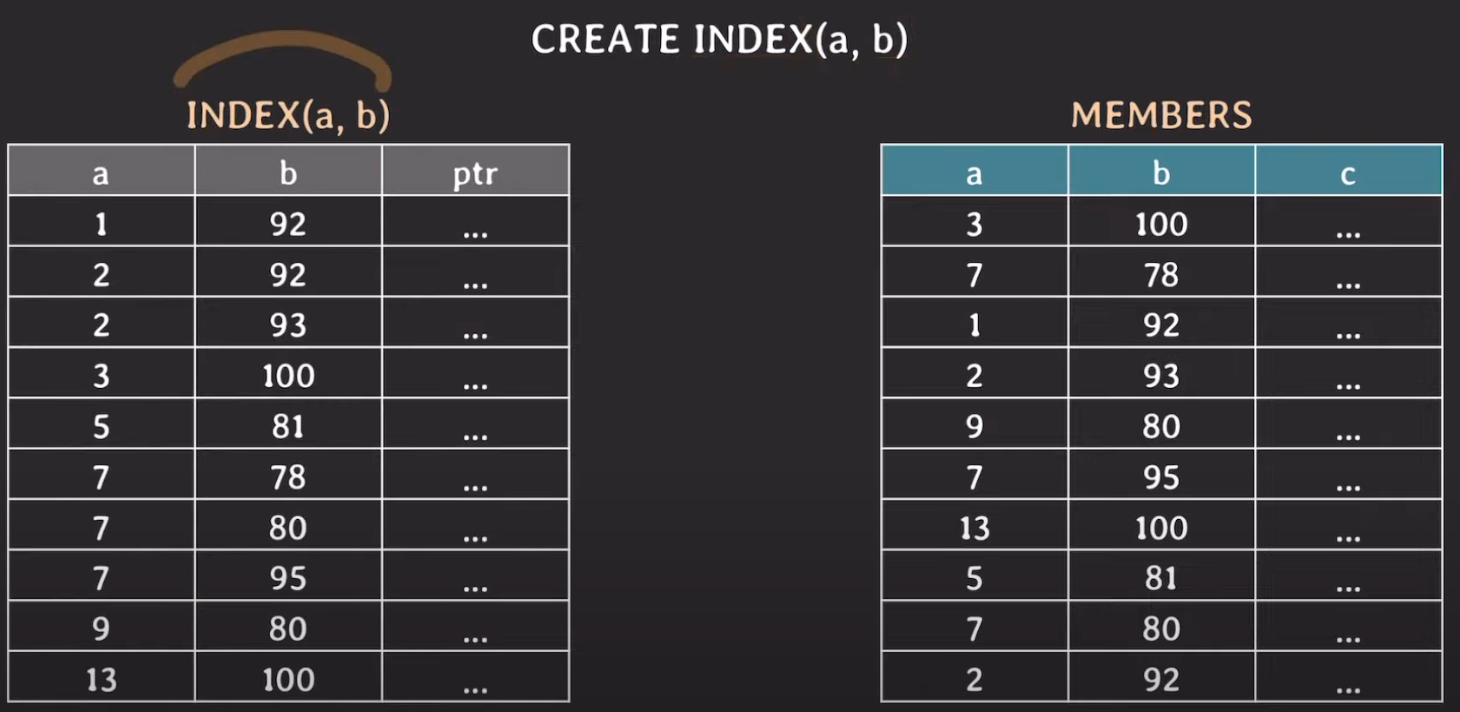
이러한 문제를 해결하기 위해 a, b 컬럼을 묶어서 복합 인덱스로 설정해줬다. 여기서 주목할점은 인덱스로 설정된 컬럼의 순서에 따른 정렬이다. 위 예제는 a컬럼이 앞에 왔기 1차적으로 a컬럼에 대해 정렬하고 그 다음으로 b컬럼에 대해 정렬한다.
예시 3
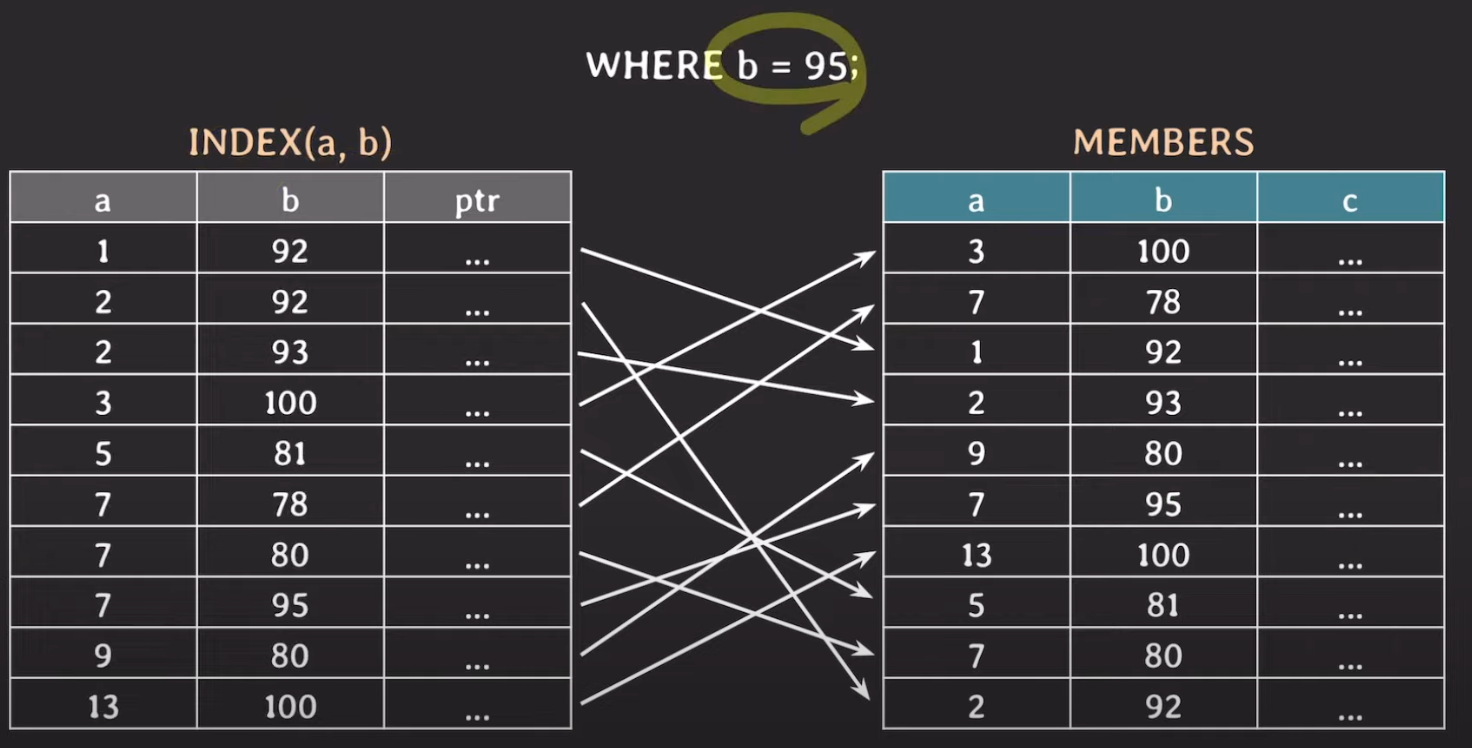
그렇다면 WHERE b = 95 라는 조건절은 어떻게 처리가 될까? 사진을 보면 알겠지만 현재 인덱스는 a, b에 대해 복합 인덱스로 잡혀있는 상황이다. a컬럼이 복합 인덱스에서 앞쪽에 위치해있기 때문에 a컬럼에 대해서 1차적으로 정렬이 되어있는 상황이다. 그리고 그 결과에 따라 b컬럼이 정렬되어있다. 따라서 이러한 상황에서는 성능이 제대로 나올 수 없으며 오히려 테이블 풀 스캔을 하는 것이 나을 수도 있다. 따라서 b에 대해 따로 인덱스를 만들어줘야 제대로 인덱스를 태울 수 있다.
예시 4
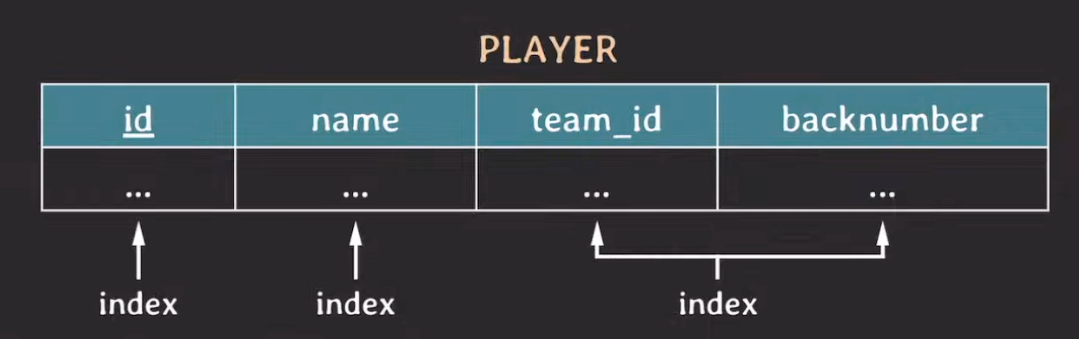
1. WHERE team_id = 110
team_id, backnumber 복합 인덱스를 정상적으로 사용한다.
2. WHERE team_id = 110 AND backnumber = 7
team_id, backnumber 복합 인덱스를 정상적으로 사용한다.
3. WHERE backnumber = 7
backnumber는 team_id, backnumber 복합 인덱스에만 존재하는데 team_id 컬럼이 앞에 위치해있고(우선순위가 높고) 해당 컬럼을 기준으로 정렬이 되어 있기 때문에 인덱스를 정상적으로 사용할 수 없다. 따라서 테이블 풀 스캔이 발생할 수 있다.
4. WHERE team_id = 110 OR backnumber = 7
team_id 조건에 대해서는 team_id, backnumber 복합 인덱스를 사용한다. 하지만 OR 조건으로 인해 backnumber는 풀 스캔을 수행한다. 결과적으로 인덱스 가능 OR 풀스캔 이기 때문에 풀 스캔이 발생한다.
3, 4번을 모두 인덱스를 태우려면 backnumber 컬럼에 대해서도 단일 인덱스를 만들어줘야 한다.
커버링 인덱스
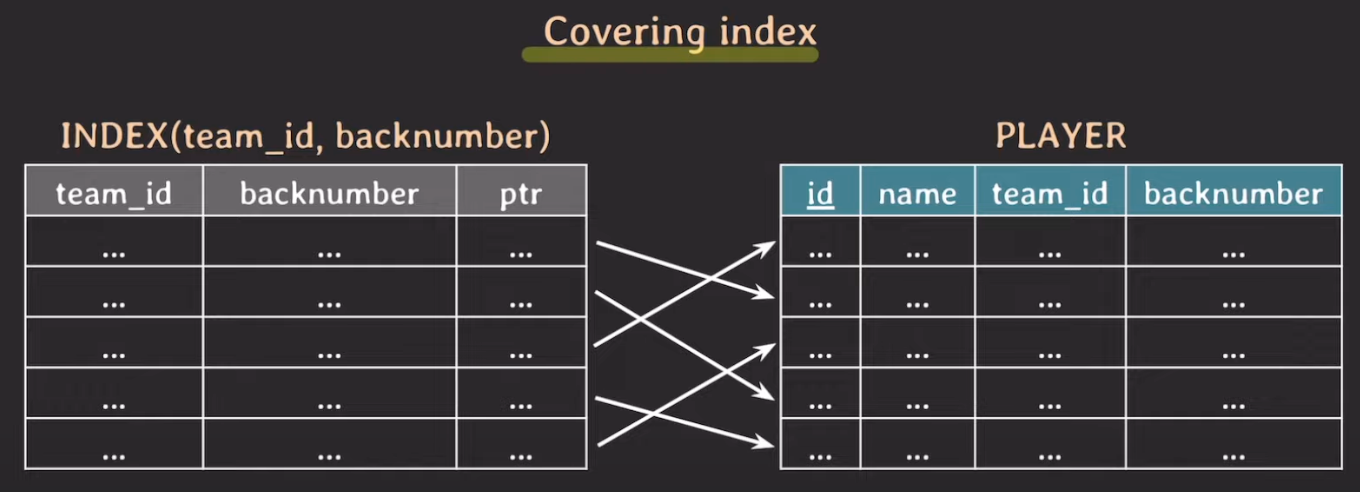
위와 같이 구성되어있다고 가정해보자. 여기에서,
SELECT team_id, backnumber FROM player WHERE team_id = 5
라는 쿼리를 날리면 어떻게 될까? 일단 인덱스를 보면 SELECT절에서 projection하는 team_id, backnumber정보를 모두 가지고 있다. 따라서 1차적으로 이진 탐색으로 WHERE team_id = 5 조건을 찾는다. 그리고 이전 예제들과는 다르게 포인터(ptr)를 통해 실제 PLAYER 테이블에 접근하지 않는다. 이미 인덱스가 2개의 정보(team_id, backnumber)를 들고 있기 때문이다.
이렇게 인덱스만으로 쿼리 결과를 커버할 수 있는 경우를 커버링 인덱스라고 한다.
Hash Index
해시 인덱스의 경우 해시 테이블을 사용하여 인덱스를 구현한다. 그리고 해시의 특성에 따라 시간 복잡도 또한 O(1)의 성능을 가지고 있다. 하지만 몇가지 단점이 존재한다.
- rehashing에 대한 부담이 존재한다.
- equality(=, !=) 비교만 가능하고 range 비교가 불가능하다.
- 복합 인덱스의 경우 인덱스가 잡혀있는 모든 컬럼에 대한 조회만 가능하다. 예를 들어 a, b 로 복합 인덱스가 걸려있다고 가정해보자. B Tree 인덱스인 경우 a 컬럼만으로도 조회가 가능했다. 하지만 Hash Index는 a, b모두를 포함하는 조건절에서만 인덱스를 활용할 수 있다.
Full Scan이 더 좋은 경우
- 테이블에 데이터가 조금 있는 경우
- 조회하려는 데이터가 테이블의 상당 부분을 차지할 때
Reference
https://www.youtube.com/watch?v=IMDH4iAQ6zM
'Coding' 카테고리의 다른 글
| 인프런 2시간만에 끝내는 코루틴 1강 ~ 7강 정리 (0) | 2024.06.12 |
|---|---|
| 200억건의 데이터를 MySQL로 마이그레이션 할 때 고려했던 개념과 튜닝 방법 정리 (0) | 2024.06.09 |
| Block IO/Non-Block IO 개념 정리 (2) | 2022.12.13 |
| Redlock 알고리즘 (0) | 2022.07.02 |
| Git 특정 커밋 수정하는 방법 (0) | 2020.09.02 |
